



So geht’s
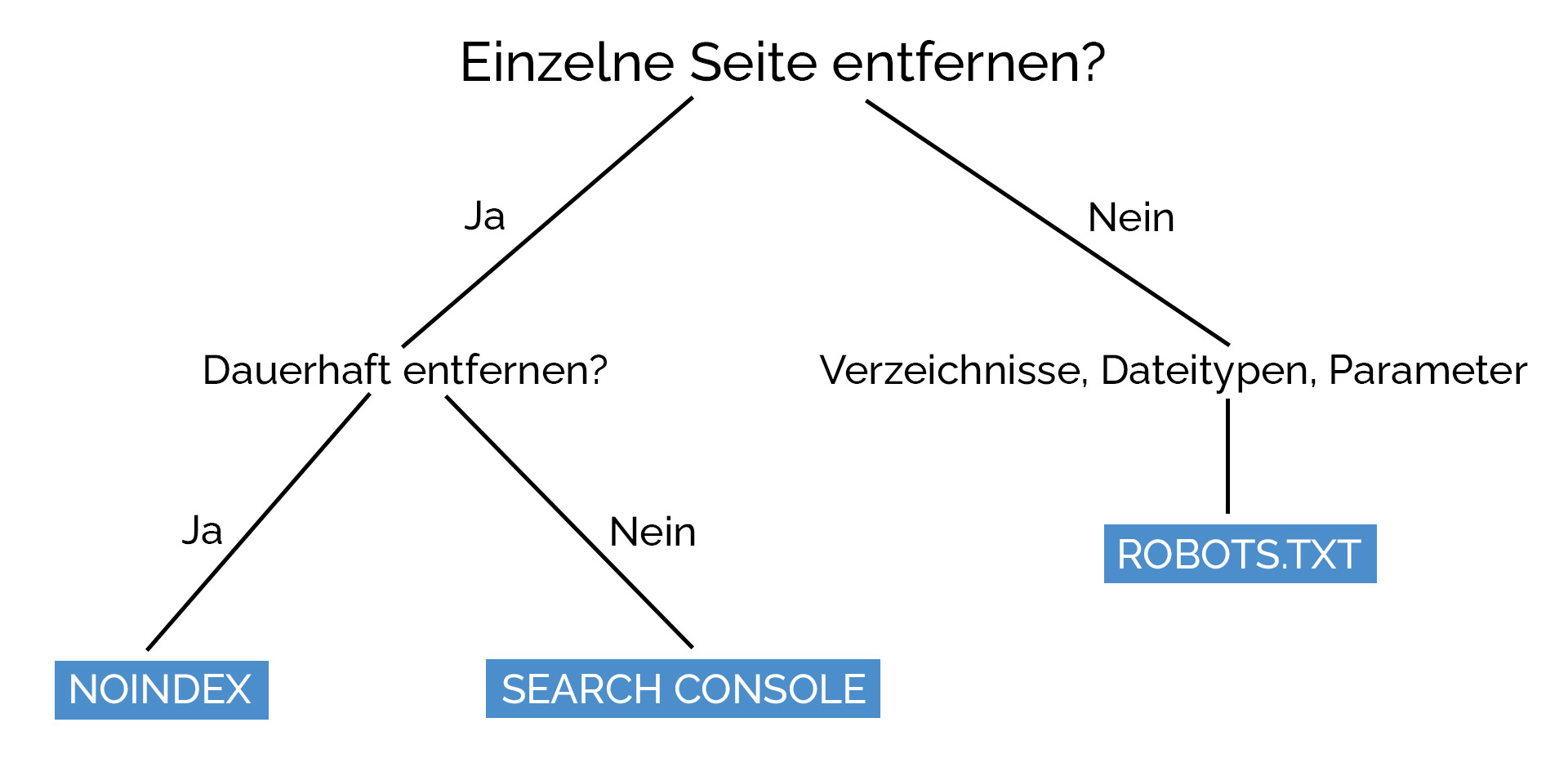
Du möchtest eine Seite aus dem Google Index löschen? Wir zeigen dir drei gängige Möglichkeiten und wann du welche nutzen solltest.
Musst du bestimmte Dateiformate wie PDF-Seiten oder ein ganzes Verzeichnis wie zum Beispiel deinen Adminbereich deindexieren? Dann solltest du dir Lösung #3 – die robots.txt Methode anschauen.
Wenn es um einzelne Seiten geht, ist meistens eine Kombination aus Lösung 1 und 2 das Mittel deiner Wahl.
Lösung #1: Sofort deindexieren mithilfe der Search Console
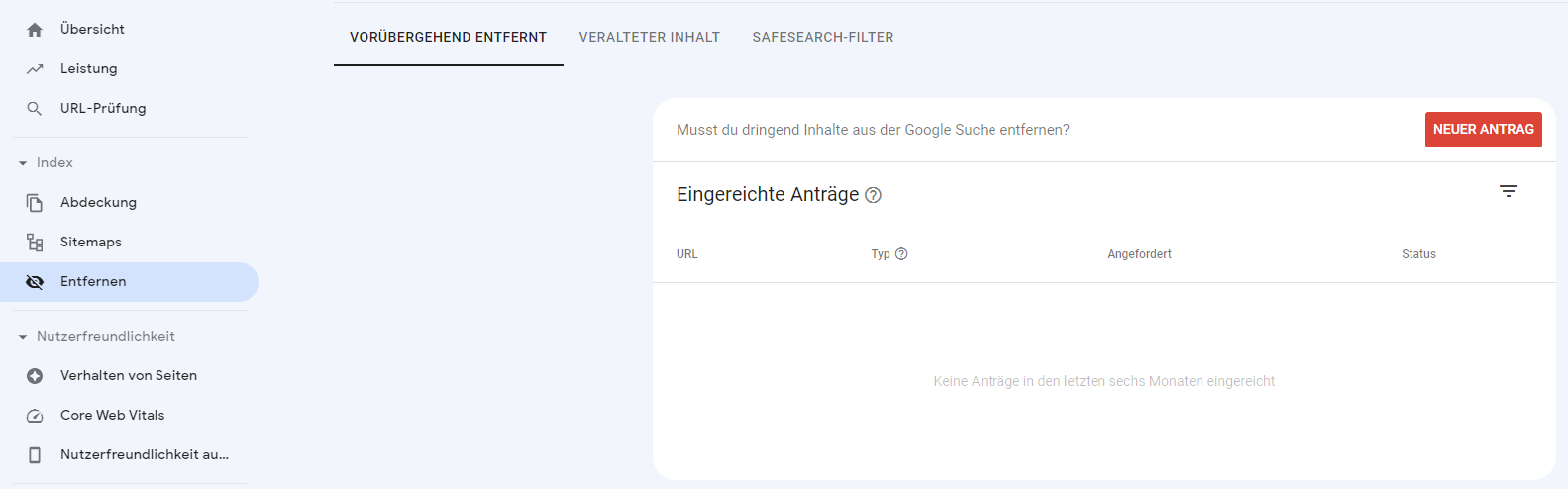
Wenn du eine Seite sofort aus dem Index schmeißen möchtest, kannst du die Search Console benutzen. Die Option findest du unter „Index > Entfernen > Neuer Antrag“.
Der Nachteil dabei: Die URL wird lediglich für ca. 6 Monate aus dem Index entfernt. Wenn du beabsichtigst, dass die URL für immer aus dem Index verschwindet, empfehle ich dir eine Kombination aus Lösung 1 für den kurzfristigen und Lösung 2 (noindex) für den langfristigen Effekt.
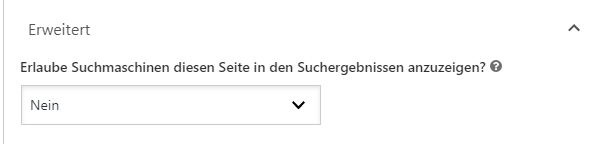
Lösung #2: Langfristig und sicher deindexieren mit noindex Tag
Die sicherste Lösung, um eine Indexierung zu verhindern ist das Meta-Tag „noindex“ im <head> Bereich einer Seite.
Dafür hinterlegst du folgenden Code möglichst weit oben vor dem öffnenden <head> Element:
Wenn du möchtest, dass nur Google die Seite nicht indexiert, kannst du diesen Code nutzen:
Falls du nicht in der Lage bist, diesen Code selbst im HTML zu hinterlegen, bietet dein CMS oder Shopsystem sicherlich einfache Möglichkeiten. In WordPress kann jedes gute SEO-Plugin wie Yoast oder All in One SEO diese Funktion abdecken. Die Einstellungen dafür findest du auf der Seite im Backend. Es können auch ganze Beitragstypen in den Grundeinstellungen mit noindex belegt werden.
Lösung #3: Verzeichnisse ausschließen mit der Robots.txt
Eine robots.txt-Datei ist eine einfache Textdatei mit Regeln, die bestimmen, welche Crawler auf welche Teile einer Website zugreifen dürfen. Es wird also nicht die Indexierung direkt, sondern das Crawling blockiert – Somit in den meisten Fällen auch die Indexierung.
Ausnahme: In einigen Fällen erhält man in der Search Console die Meldung „Indexiert, obwohl durch robots.txt blockiert„. Das liegt daran, dass die Seite möglicherweise oft verlinkt wurde und Google die URL demnach als relevant erachtet. Da Google die Seite nicht crawlen konnte, erscheinen im Snippet auch keine weiteren Informationen über die Seite. In solchen Fällen hilft nur noch noindex.
Mithilfe des „Disallow“-Befehls lassen sich Pfade, URLs oder Dateitypen ausschließen. Vorher muss der Crawler mit „User-agent“ bestimmt werden (Googlebot, Bingbot, DuckDuckBot). Da die Befehle nur für die eigene Domain gelten, wird diese im Disallow Befehl weggelassen und nur der Teil dahinter angegeben.
Pfad für alle Bots ausschließen:
User-agent:*
Disallow: /wp-admin/
PDFs für alle Bots ausschließen:
User-agent: *
Disallow: /*.pdf$
URL für Googlebot ausschließen:
User-agent: Googlebot
Disallow: /meine-url/
Pfad für alle Bots außer Google ausschließen:
User-agent: Googlebot
Disallow:
User-agent: *
Disallow: /wp-admin/